












【佳学基因检测】糖尿病风险基因检测中的多基因风险评估打分准确性如何?
糖尿病风险评估基因检测导读:
患病率不断上升的 2 型糖尿病 (T2D) 是一项重大的全球公共卫生挑战。 肥胖、不健康的饮食和低体力活动是导致 T2D 患病率上升的主要决定因素之一。 此外,糖尿病的家族史和遗传风险也在 T2D 的发展过程中发挥作用。 因此,非常优选用于早期识别 T2D 高风险个体的解决方案,以进行 T2D 的早期靶向检测、预防和干预。 最近,佳学基因检测使用基于基因组的新型多基因风险评分 (PRS) 来提高风险预测的准确性,支持针对 T2D 风险最高的人群进行预防性干预。 因此,《糖尿病风险基因检测中的多基因风险评估打分准确性如何》的目的是评估额外的 PRS 测试信息(作为总体风险评估的一部分)的成本效用,然后在超过估计的 10 年 T2D 总体风险时进行生活方式干预和额外的药物治疗。 对于成本效用分析,构建了具有概率敏感性分析的个体级状态转换模型。 在基本案例中应用了 1 年的周期长度和生命周期时间范围。 成本和 QALYs 使用了 3% 的折扣率。 计算成本效益可接受性曲线 (CEAC) 和完美信息预期值 (EVPI) 的估计值以帮助决策者。 使用有针对性的 PRS 策略将 12.4 个百分点的个人重新分类为非常高风险的个人,这些人最初仅使用通常的策略就会被归类为高风险。 在整个生命周期内,有针对性的 PRS 是一种主导策略(即成本更低、更有效)。 单向和情景敏感性分析表明,结果在几乎所有模拟中仍然占主导地位。 结果表明,与目前的 T2D 风险筛查方法相比,PRS 在风险筛查方面为普通人群提供了适度的附加值,从而可能节省成本并提高生活质量。
糖尿病风险基因检测中的多基因风险评估打分准确性
在 UKB 中收集的总共 456,451 名参与者被随机分为 UKB 测试数据集(n = 182,422)和验证数据集(n = 274,029)。 参与者的平均年龄为 57 岁,在测试和验证数据集中,54% 的参与者为女性。 在测试数据集中有近 5.494% (n = 10,023) 的参与者是案例,在验证数据集中有 5.575% (n = 15,277) 的参与者。 所有这些因素在基线时都具有可比性。 基线特征的详细信息如表 1 所示。
表1:在测试数据集和验证数据集中的基线特征 (M ± SD or %)
| 变量 | UKB 测试数据集 (n = 182,422) | UKB验证数据集 (n = 274,029) | 统计数据和p-值 |
| 性别 | |||
| 男性 (%) | 83,200 (45.609) | 125,670 (45.860) | x2 = 2.783, p = 0.095 |
| 女性 (%) | 99,222 (54.391) | 148,359 (54.140) | |
| 年龄 (岁) | 56.777 ± 8.020 | 56.809 ± 8.009 | t = −1.341, p = 0.179 |
| 身体指标 | |||
| BMI (kg/m2) | 27.388 ± 4.758 | 27.404 ± 4.765 | t = −1.087, p = 0.277 |
| WC (cm) | 90.250 ± 13.485 | 90.306 ± 13.505 | t = −1.135, p = 0.175 |
| DBP (mmHg) | 82.174 ± 10.311 | 82.171 ± 10.313 | t = −0.118, p = 0.906 |
| SBP (mmHg) | 139.924 ± 19.000 | 139.917 ± 19.000 | t = −0.116, p = 0.908 |
| 临床指标 | |||
| CL (mmol/L) | 5.711 ± 1.115 | 5.710 ± 1.117 | t = −0.314, p = 0.753 |
| GL (mmol/L) | 5.119 ± 1.134 | 5.118 ± 1.132 | t = 0.150, p = 0.881 |
| TL (mmol/L) | 1.753 ± 1.002 | 1.753 ± 1.000 | t = −0.010, p = 0.992 |
| HDL (mmol/L) | 1.452 ± 0.357 | 1.453 ± 0.358 | t = −0.625, p = 0.532 |
| LDL (mmol/L) | 3.556 ± 0.839 | 3.556 ± 0.841 | t = −0.083, p = 0.934 |
| 2型糖尿病 | |||
| 病例 (%) | 10,023 (5.494) | 15,277 (5.575) | x2 = 1.342, p = 0.247 |
| 对照 (%) | 172,399 (94.506) | 258,752 (94.425) |
为了获得最佳的 PRS 模型,糖尿病多基因风险打分基因检测生成了总共 16 个由 PRSice-2 软件实现的候选 PRS 模型。 糖尿病多基因风险打分基因检测在 UKB 测试数据集中评估了这 16 个 PRS 模型的性能,并选择了最好的模型进行进一步的验证分析。 这 16 个候选 PRS 模型的 AUC 范围从 0.691 到 0.792(表 2)。 糖尿病多基因风险打分基因检测根据 25,454 个 SNP 选择了具有最高 AUC [AUC = 0.792, 95% CI: (0.787, 0.796)] 的最佳 PRS 模型,当 p≤5×10−2 且 r2 < 0.2 时。 测试和验证数据集不同比例的AUC如表3所示。糖尿病多基因风险打分基因检测可以看到不同比例的AUC非常接近,范围为0.791到0.795。 40-60% 比率的 AUC 在验证数据集中具有最佳性能 [AUC = 0.795, 95% CI: (0.790, 0.800)]。 图 1 提供了 PRS 模型构建、测试和验证的其他详细信息。
表 2:不同多基因风险评分 (PRS) 模型对 2 型糖尿病 (T2D) 的预测能力。
| 调数调节 | SNP数目 | AUC (95% CI) |
| p≤ 5× 10−8 和 r2 < 0.2 | 363 | 0.706 (0.701–0.711) |
| p≤ 5× 10−8 和 r2 < 0.4 | 486 | 0.702 (0.697–0.707) |
| p≤ 5× 10−8 和 r2 < 0.6 | 670 | 0.696 (0.691–0.701) |
| p≤ 5× 10−8 和 r2 < 0.8 | 957 | 0.691 (0.686–0.697) |
| p≤ 5× 10−6 和 r2 < 0.2 | 750 | 0.715 (0.710–0.720) |
| p≤ 5× 10−6 和 r2 < 0.4 | 1,013 | 0.709 (0.704–0.714) |
| p≤ 5× 10−6 和 r2 < 0.6 | 1,335 | 0.701 (0.696–0.706) |
| p≤ 5× 10−6 和 r2 < 0.8 | 1,853 | 0.696 (0.691–0.701) |
| p≤ 5× 10−4 和 r2 < 0.2 | 2,616 | 0.736 (0.732–0.741) |
| p≤ 5× 10−4 和 r2 < 0.4 | 3,394 | 0.726 (0.721–0.731) |
| p≤ 5× 10−4 和 r2 < 0.6 | 4,299 | 0.715 (0.710–0.720) |
| p≤ 5× 10−4 和 r2 < 0.8 | 5,690 | 0.708 (0.703–0.713) |
| p≤ 5× 10−2 和 r2 < 0.2 | 25,454 | 0.792 (0.787–0.796) |
| p≤ 5× 10−2 和 r2 < 0.4 | 32,600 | 0.782 (0.777–0.787) |
| p≤ 5× 10−2 和 r2 < 0.6 | 40,001 | 0.771 (0.766–0.776) |
| p≤ 5× 10−2 和 r2 < 0.8 | 50,224 | 0.760 (0.755–0.765) |
表3:当 p≤5×10−2 且 r2 < 0.2 时,不同比例的测试和验证数据集的接受者操作特征曲线 (AUC) 下的面积
| 数据集 | 30–70% | 40–60% | 50–50% | 60–40% | 70–30% |
| 测试 | 0.791 | 0.792 | 0.794 | 0.795 | 0.794 |
| (0.781–0.791) | (0.787–0.796) | (0.790–0.800) | (0.791–0.799) | (0.790–0.799) | |
| 验证 | 0.794 | 0.795 | 0.793 | 0.792 | 0.791 |
| (0.790–0.799) | (0.790–0.800) | (0.789–0.797) | (0.787–0.796) | (0.781–0.791) |
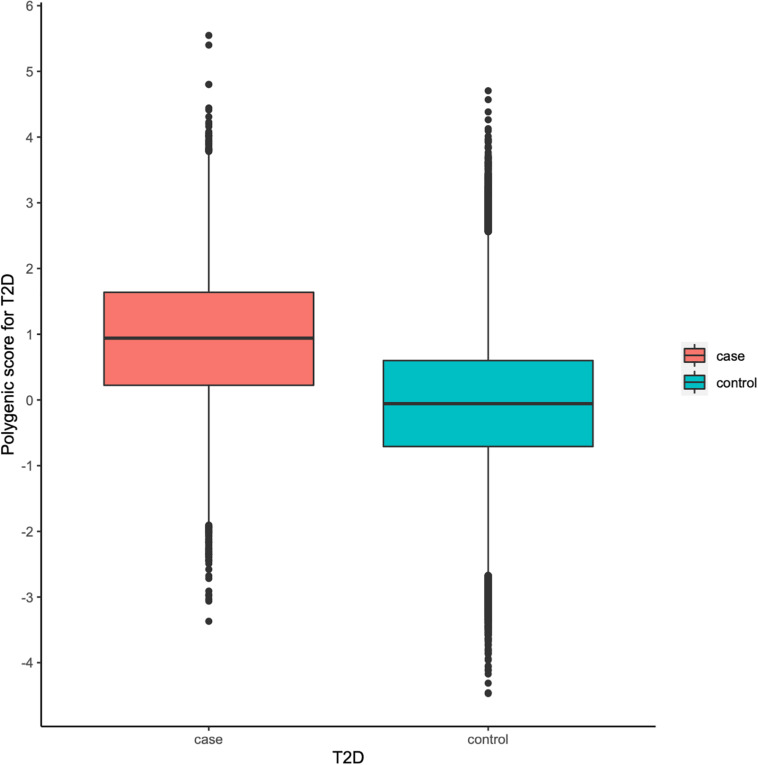
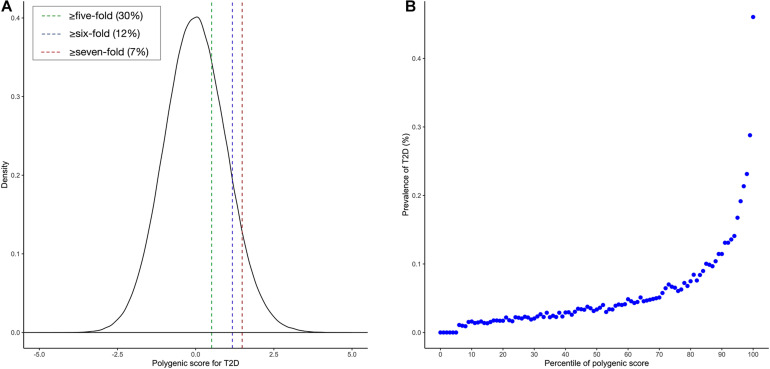
为了便于解释,糖尿病多基因风险打分基因检测将 PRS 缩放为零均值和一个标准差。 糖尿病多基因风险打分基因检测调查了 PRS 模型是否可以识别 T2D 高风险个体。 图 2 显示,患有 T2D 的个体的标准化 PRS 中位数为 0.941,而没有患有 T2D 的个体为 -0.056,差异为 0.997 (p < 0.00001)。 从图 3A 中,糖尿病多基因风险打分基因检测发现标准化的 PRS 近似于整个人群的正态分布,T2D 的经验风险在分布的右尾急剧上升。 PRS 模型确定了将近 30% 的人口风险大于或等于五倍,12% 的人口风险大于或等于六倍,以及前 7% 的人口风险大于或等于七倍 对于图 3A 所示的 T2D。 然后,糖尿病多基因风险打分基因检测根据 PRS 的百分位数对人群进行分层,并将前 10 个百分位数定义为“高风险”组,将后 10 个百分位数定义为“低风险”组。 图 3B 显示 T2D 的患病率随着 PRS 模型的百分位数而增加。 在 30,174 人中,“高风险”组有 5,642 例(18.698%),而“低风险”组只有 282 例(0.935%),对应于 T2D 风险比前者增加了近 20 倍 前 10 个百分位数与后 10 个百分位数。
我们进一步调查了多基因预测因子、性别、年龄、身体测量值和临床因素在识别 T2D 高风险个体中的作用。 表 4 显示,仅将 PRS 纳入预测模型而未调整任何其他协变量的模型 3 的 AUC 在测试数据集中为 0.749 [95% CI: (0.744,0.754)],在测试数据集中为 0.755 [95% CI: (0.752 , 0.755)] 在验证数据集中。 有趣的是,如果仅将性别、年龄和祖先的前 10 个主要成分纳入模型,AUC 为 0.667 [95% CI: (0.663, 0.672)]。 加入PRS后,AUC达到0.795[95% CI: (0.790, 0.800)],比model2提高了约13%。 模型 4(即同时考虑性别、年龄、PC、BMI、WC、DBP、SBP、GL、CL、HDL、LDL 和 TL)的 AUC 为 0.880 [95% CI: (0.878, 0.888)] 并提高到 将 PRS 添加到模型中时,验证数据集中的 0.901 [95% CI: (0.897, 0.904)]。 简而言之,多基因评分确实有助于识别 T2D 的高危个体,而 T2D 相关协变量的作用也有助于提高预测准确性。 如表 5 所示,PRS、性别、年龄、身体测量值和大多数临床因素都与 T2D 显着相关 (p < 0.0001)。
表 4:测试和验证数据集中不同模型的接受者操作特征曲线 (AUC) 下的面积。
| 数据集 | 平均值 | 模型2 | 模型3 | 模型1 | 模型4 | 模型5 |
| 测试 | −0.003 | 0.671 (0.666–0.676) | 0.749 (0.744–0.754) | 0.792 (0.787–0.796) | 0.886 (0.882–0.889) | 0.902 (0.899–0.905) |
| 验证 | −0.003 | 0.667 (0.663–0.672) | 0.755 (0.752–0.755) | 0.795 (0.790–0.800) | 0.882 (0.878–0.888) | 0.901 (0.897–0.904) |
表 5:验证数据集中 model5 下的参数估计
| 变量 | Estimate beta | 标准差 | Z | p-value |
| (Intercept) | 24.500 | 0.495 | 49.474 | < 2× 10−16 |
| PRS | 12370.000 | 167.400 | 73.943 | < 2× 10−16 |
| CL | −0.591 | 0.057 | −10.377 | < 2× 10−16 |
| HDL | 0.051 | 0.063 | 0.876 | 0.381 |
| LDL | 0.010 | 0.068 | 0.140 | 0.888 |
| TL | 0.285 | 0.013 | 21.826 | < 2× 10−16 |
| Sex | −0.214 | 0.028 | −7.731 | 1.070× 10−14 |
| WC | 0.045 | 0.002 | 28.356 | < 2× 10−16 |
| BMI | 0.036 | 0.004 | 9.325 | < 2× 10−16 |
| Age | 0.060 | 0.002 | 38.401 | < 2× 10−16 |
| DBP | −0.018 | 0.001 | −13.928 | < 2× 10−16 |
| SBP | 0.005 | 0.001 | 7.626 | 2.410× 10−16 |
| GL | 0.449 | 0.006 | 69.917 | < 2× 10−16 |
| PC10 | 0.020 | 0.004 | 4.726 | 2.280× 10−16 |
关于糖尿病多基因风险评分的准确性分析
糖尿病多基因风险评分的准确性研究组的结果表明,在针对性别、年龄和祖先的前 10 个主要成分进行调整后,最佳 PRS 模型的 AUC 为 0.795。 它表明 PRS 确实有助于识别处于发展 T2D 高风险中的个体。 同时,病例和对照组的 PRS 分布存在显着差异,即病例的 PRS 中位数 (0.941) 远高于对照组 (-0.056)。 此外,大约 30% 的参与者患 T2D 的风险增加了 5 倍以上,12% 的参与者的风险增加了 6 倍以上,而前 7% 的参与者的风险增加了 7 倍以上。 特别是,根据百分位数分层的 PRS 表明,“高风险”群体与 T2D 风险密切相关。
上述结果表明,糖尿病多基因风险评分的准确性研究组的 PRS 模型可以用作识别 T2D 高风险个体的有力工具; 改进了先前研究。PRS 模型的 AUC 仅使用已发表的三个 SNP 进行评估,在 6,078 个人中易患 T2D 为 0.571(Weedon 等人,2006)。 在包含更多 SNP 之后,糖尿病多基因风险打分研究构建了具有 18 个 SNP 的 PRS 模型并获得了 0.600 的 AUC。 后来对 22 个 SNP 进行的一项研究的 AUC 为 0.570,并允许确定 3.0% 的人群的 T2D 风险是平均风险的两倍或更高。 值得注意的是,与糖尿病多基因风险评分的准确性研究组的研究(AUC = 0.755)相比,上述三项样本量较小(范围从 4,907 到 39,117)和 SNP 数量较少(范围从 3 到 22)的研究的预测性能相对较差,糖尿病多基因风险评分的准确性研究组的研究(AUC = 0.755)在 274,029 中有 25,454 个 SNP 个人。
此外,糖尿病多基因风险评分的准确性研究组强调非遗传风险因素的作用,即性别、年龄、身体测量和临床因素。 在调整性别和年龄时,Meigs 等人 (2008) 在 2,776 个人中获得了 0.581 的 AUC,Vassy 等人 (2014) 在 11,883 人中提供了 0.726 的 AUC,以及 Läll 等人的 AUC(2017) 达到 0.740。 有趣的是,这项研究处理了 288,978 个人的近 700 万个变异,在加上性别和年龄后仅产生了 0.730 的 AUC,小于我们的 (0.795),仅包括 25,454 个 SNP。 他们进一步报告说,3.5% 的人口遗传了一种遗传倾向,使患 T2D 的风险增加了三倍以上,0.2% 的人口遗传了大于或等于四倍的风险,0.05% 的人口遗传了大于或等于五倍的风险 . 他们的研究在四个方面与糖尿病多基因风险评分的准确性研究组的不同。 首先,糖尿病多基因风险评分的准确性研究组的研究样本量更大(456,451 对 409,258)。 其次,糖尿病多基因风险评分的准确性研究组首先根据全基因组关联 p 值 (p≤5×10−2) 执行 SNP 选择,以便糖尿病多基因风险评分的准确性研究组在 PRS 模型中包含更多预测性 SNP (25,454) 并避免虚假 SNP。 第三,他们使用祖先的前 4 个主成分,而糖尿病多基因风险评分的准确性研究组使用祖先的前 10 个主成分,以便更好地控制人口分层。 第四,糖尿病多基因风险评分的准确性研究组基于计算效率更高和可扩展性更高的 PRSice-2 软件生成 PRS,而他们使用 LDpred 程序,它比 PRSice-2 慢得多。 这些差异解释了为什么糖尿病多基因风险评分的准确性研究组的 PRS 模型具有更好的预测能力。 当然,糖尿病多基因风险评分的准确性研究组也尝试加入更多的非遗传风险因素,AUC从0.755增加到0.901。 因此,糖尿病多基因风险评分的准确性研究组的研究可以更准确地识别出患 T2D 的低风险和高风险个体。
糖尿病多基因风险评分的准确性研究组的研究具有多重优势。 首先,糖尿病多基因风险评分的准确性研究组基于UKB数据集构建PRS模型,该数据集是全球最大的前瞻性队列研究之一,个人信息全面丰富,基因分型数据质量高。 其次,糖尿病多基因风险评分的准确性研究组三步过滤程序将 SNP 选择到 PRS 模型中。 这种方法实现起来很简单,并且具有很好的预测性能。 第三,糖尿病多基因风险评分的准确性研究组在预测模型中加入了新的物理测量值和临床因素(即 WC、DBP、HDL 和 LDL),以提高预测准确性。 第四,糖尿病多基因风险评分的准确性研究组采用了新的 PRS 软件 PRSice-2,该软件已被证明在预测准确性和计算速度方面优于其他竞争方法和软件。
尽管本研究在识别患 T2D 风险增加的个体方面做出了重要贡献; 但是,存在一个主要限制。 UKB 数据集中的个体主要是欧洲血统; 此处计算的特定 PRS 可能对其他种族群体没有最佳预测能力,因为等位基因频率、LD 模式和常见 SNP 的效应大小在具有不同种族背景的人群中可能不同。
总之,糖尿病多基因风险评分的准确性研究组的研究结果表明,即使仅基于遗传数据,PRS 模型也能高度预测 T2D 风险,并且在包含非遗传风险因素后预测准确性提高,表明我们的 PRS 模型可以用作预防疾病的有力工具 T2D 筛查。
(责任编辑:佳学基因)